在 9 月 3 日,Gru.ai 在 SWE-Bench-Verified 評估最新發布的數據中以 45.2% 的高分排名第一。SWE-Bench-Verified 是 OpenAI 聯合 SWE 發布測試集,旨在更可靠的評估 AI 解決實際軟件問題的能力。該測試集經由人工驗證打標,被認為是評估 AI 軟件工程能力的最權威標準。
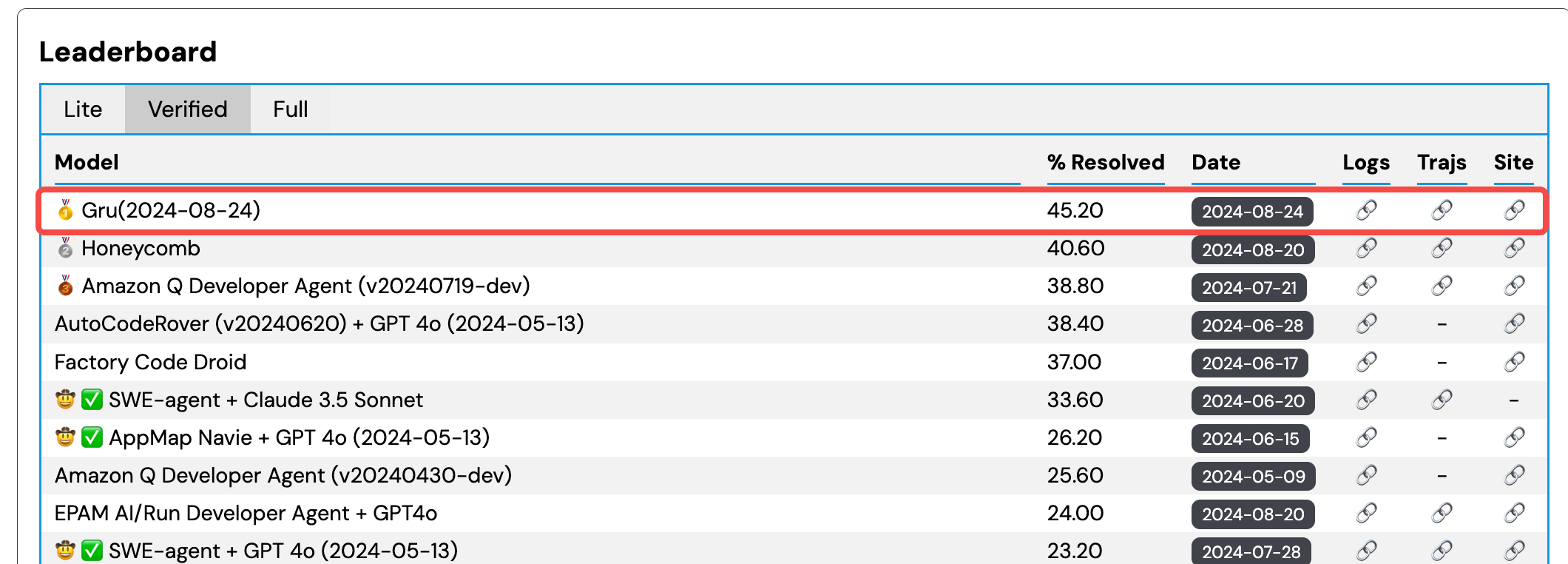
本次參評登頂的 Coding Agent 是來自 Gru.ai 的 Bug Fix Gru。根據 Gru 團隊的博客,他們提供給 Bug Fix Gru 完整的運行環境及豐富的開發工具,這是獲取高分的基礎,而工作流程,多模態支持,Rag 能力的添加都有效提高了得分。值得關注的是,Gru 團隊著重提到了他們有一個評估流程來評估任何改動帶來的影響。
Gru.ai 是一家提供軟件工程 Agent(智能體)的公司,提供四種 Agent:
-
Assistant Gru:幫助用戶解決獨立的技術問題,該產品可直接在網站注冊使用。
-
Test Gru:基于用戶代碼補全單測的 Agent,目前該產品僅面相企業開放。
-
Bug Fix Gru:基于 Github Issue,直接提交 Patch,目前該產品僅面向企業開放。
-
Babel Gru:基于技術文檔生成軟件,目前該產品仍處于實驗室階段。
Gru 在今年一月披露了一筆 550 萬美金的融資,投資方為云九資本和峰瑞資本。在 2023 年到 2024 年兩年間,國際上大量的資金涌入代碼 Agent 領域,如 Devin、Cosine.sh、Factory、Codium.ai 等,但國內針對軟件工程領域 AI 的投資仍然較少。Gru 團隊擁有豐富的軟件工程和 AI 實踐經驗,CEO 張海龍曾是開源中國及 Coding.net 創始人。
隨著資金和大公司的視線逐步從大模型轉向上層應用,AI 行業的主要進步方向已經開始轉向處理復雜精密的任務,而非簡單的生成文本內容。而 Gru.ai 的成功登頂,標志著國人團隊在 Agent 領域的工程技術能力處于第一梯隊。