
在大模型蓬勃發(fā)展的推動下,人工智能正牽動著一場覆蓋全行業(yè)、全領(lǐng)域的科技變革,而開源大模型已在這場變革中樹立起不可或缺的地位。革命性的自然語言處理和生成能力賦予了企業(yè)和開發(fā)者前所未有的機會,構(gòu)建更智能、更高效的應(yīng)用和服務(wù)。在商業(yè)應(yīng)用、數(shù)據(jù)分析、教育培訓(xùn)等領(lǐng)域展現(xiàn)出巨大潛力。
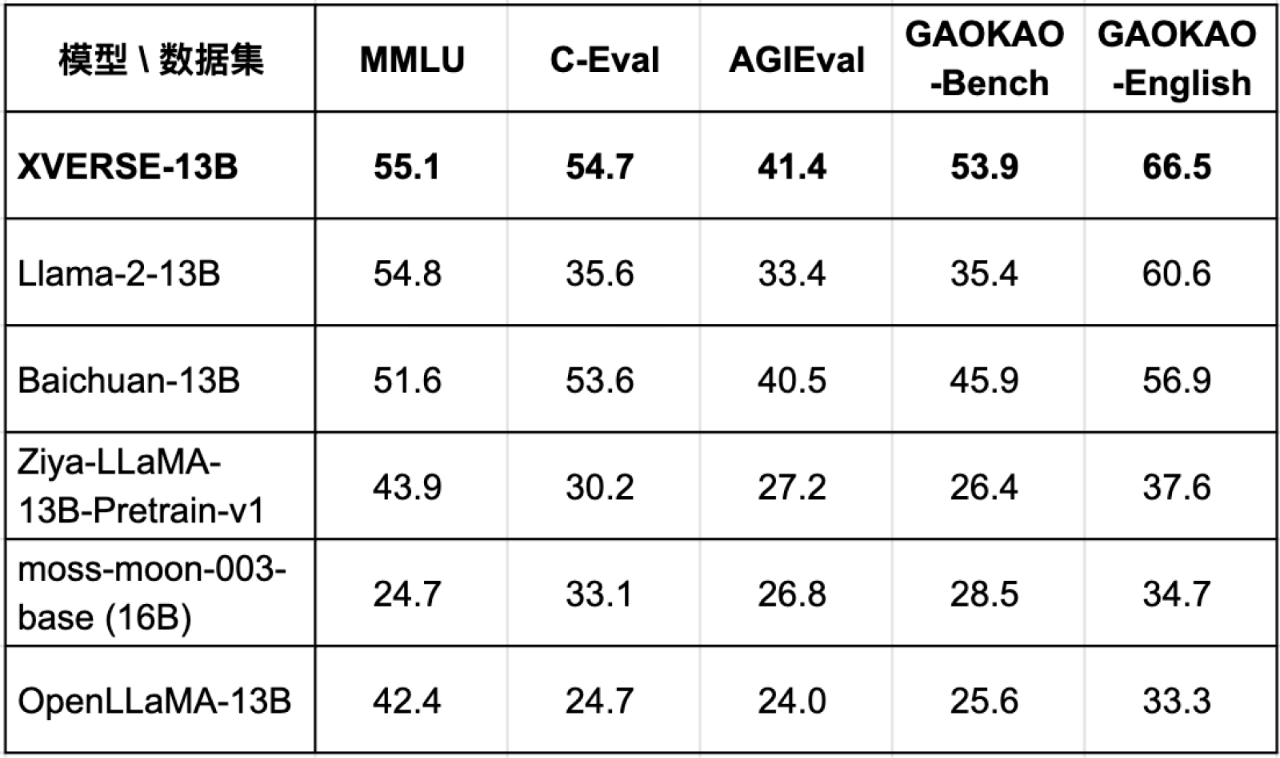
8月7日,元象XVERSE公司宣布開源其百億參數(shù)的高性能通用大模型XVERSE-13B,可免費商用。據(jù)官方介紹,XVERSE-13B是目前同尺寸中效果最好的多語言大模型,在多項權(quán)威的標準中文和英文測評中,性能超越了Llama-2-13B、Baichuan-13B等國內(nèi)外開源模型代表。
對此,「大模型之家」獨家對話元象XVERSE,就開源大模型對企業(yè)、行業(yè)的價值與影響等多角度帶來專業(yè)的觀點與分析。以開源打造互聯(lián)網(wǎng)時代主流模式
元象XVERSE向大模型之家表示,XVERSE-13B是完全開源,支持免費商用。企業(yè)本意就是為了推動國產(chǎn)大模型開源生態(tài)與產(chǎn)業(yè)應(yīng)用的繁榮發(fā)展。如果技術(shù)發(fā)展,能推動生態(tài)和產(chǎn)業(yè)發(fā)展,我們自然能創(chuàng)造更多、更大的價值。

開源性質(zhì)將促進知識的共享和合作,打破信息孤島,使知識普惠化成為可能。這將使得知識和技術(shù)不再受限于特定的機構(gòu)或地區(qū),有助于縮小數(shù)字鴻溝,提高社會中更多人的數(shù)字素養(yǎng)水平。
強大自然語言處理和生成能力將在各個行業(yè)和領(lǐng)域產(chǎn)生深遠影響。在醫(yī)療領(lǐng)域,它可以用于輔助醫(yī)療診斷、藥物研發(fā)等;在金融領(lǐng)域,可以用于智能投資分析、風(fēng)險評估等;在教育領(lǐng)域,可以推動個性化教育、智能輔導(dǎo)等;在媒體領(lǐng)域,可以改善內(nèi)容生成和新聞報道。
除此之外,開源大模型還有助于加速科研進展,為研究人員提供更強大的工具,推動各領(lǐng)域的創(chuàng)新。據(jù)元象XVERSE介紹,哈爾濱工業(yè)大學(xué)已經(jīng)率先使用XVERSE-13B大模型推進相關(guān)研究工作。哈工大計算機科學(xué)與技術(shù)學(xué)院張偉男教授表示,“開源是互聯(lián)網(wǎng)時代主流模式,不僅能貢獻社區(qū),推動技術(shù)持續(xù)創(chuàng)新,還能利用協(xié)同解決算法透明性、穩(wěn)定性、公眾信任度等共性問題。”多數(shù)據(jù)領(lǐng)跑,讓AI寫作“用事實說話”
XVERSE-13B大模型基于標準Transformer結(jié)構(gòu),在1.4萬億高質(zhì)量、多樣化tokens的訓(xùn)練數(shù)據(jù)上,從零訓(xùn)練(train from scatch)了130億參數(shù)大模型,支持40多種語言,上下文窗口大小為8192。
1.4萬億tokens為XVERSE-13B帶來了更豐富和多樣化的語言知識,能夠處理更復(fù)雜和多變的自然語言任務(wù)。8192的上下文窗口大小,說明模型能夠捕捉到更長距離的語義關(guān)系,但也需要更多的計算資源。
元象XVERSE向大模型之家介紹:“訓(xùn)練XVERSE-13B我們使用的是千卡算力,網(wǎng)絡(luò)采用ROCE(RDMA over Converged Ethernet)是一種基于以太網(wǎng)的RDMA(Remote Direct Memory Access)協(xié)議,單機規(guī)格1.6Tbps。提升推理速度和效果是我們正在探索的工作,也是后續(xù)的優(yōu)化方向。”
除此之外,大模型之家注意到在XVERSE-13B的測評過程中選擇了AGIEval、GAOKAO-Bench等評測方法進行測試,這些評測方法主要為圍繞一些國內(nèi)外專業(yè)的官方入學(xué)和職業(yè)資格考試。
在回答“當(dāng)面對非官方中文語言理解和邏輯推理時將如何避免XVERSE-13B回答出現(xiàn)‘幻覺’?”的問題時,對此元象XVERSE表示:好的團隊基因是大模型獲得良好的效果的重要原因。元象在2021年成立時就有完整的AI技術(shù)與人才布局。目前大模型團隊有多位來自騰訊、百度和IDEA研究院等機構(gòu)的技術(shù)專家,在NLP和搜索領(lǐng)域有深厚技術(shù)積累,對語言數(shù)據(jù)和高質(zhì)量語料理解深入,在快速迭代模型方面經(jīng)驗豐富。
為了避免回答出現(xiàn)幻覺,元象采用了多樣化且準確的數(shù)據(jù)進行訓(xùn)練,讓模型盡可能地多學(xué)習(xí)。從擬人的角度看,其實人有時候也會出現(xiàn)“空耳”以及理解偏差的情況,但元象會努力讓模型避免此類問題。從2022年開始,公司就針對“基于動態(tài)知識引入的事實一致性對話生成”這一關(guān)鍵核心課題進行深入研究,希望在結(jié)合上下文與背景信息時,減少與事實不符或錯誤背景描述的情況,讓AI實現(xiàn)從寫作“自然流暢”到“用事實說話”的技術(shù)跨越。深度結(jié)合自身業(yè)務(wù),以AI驅(qū)動“端云協(xié)同”3D互動技術(shù)
元象作為國內(nèi)領(lǐng)先的AI與元宇宙技術(shù)服務(wù)公司,致力于打造AI驅(qū)動的3D內(nèi)容生產(chǎn)與消費一站式平臺,通過大模型賦能自身業(yè)務(wù)將成為公司未來發(fā)展的重要方向。元象表示:XVERSE-13B是一個通用大模型,能與任何有需要的行業(yè)和業(yè)務(wù)結(jié)合,企業(yè)認為它在醫(yī)療、教育、文旅、金融和娛樂等行業(yè)將具有更大的發(fā)展前景。
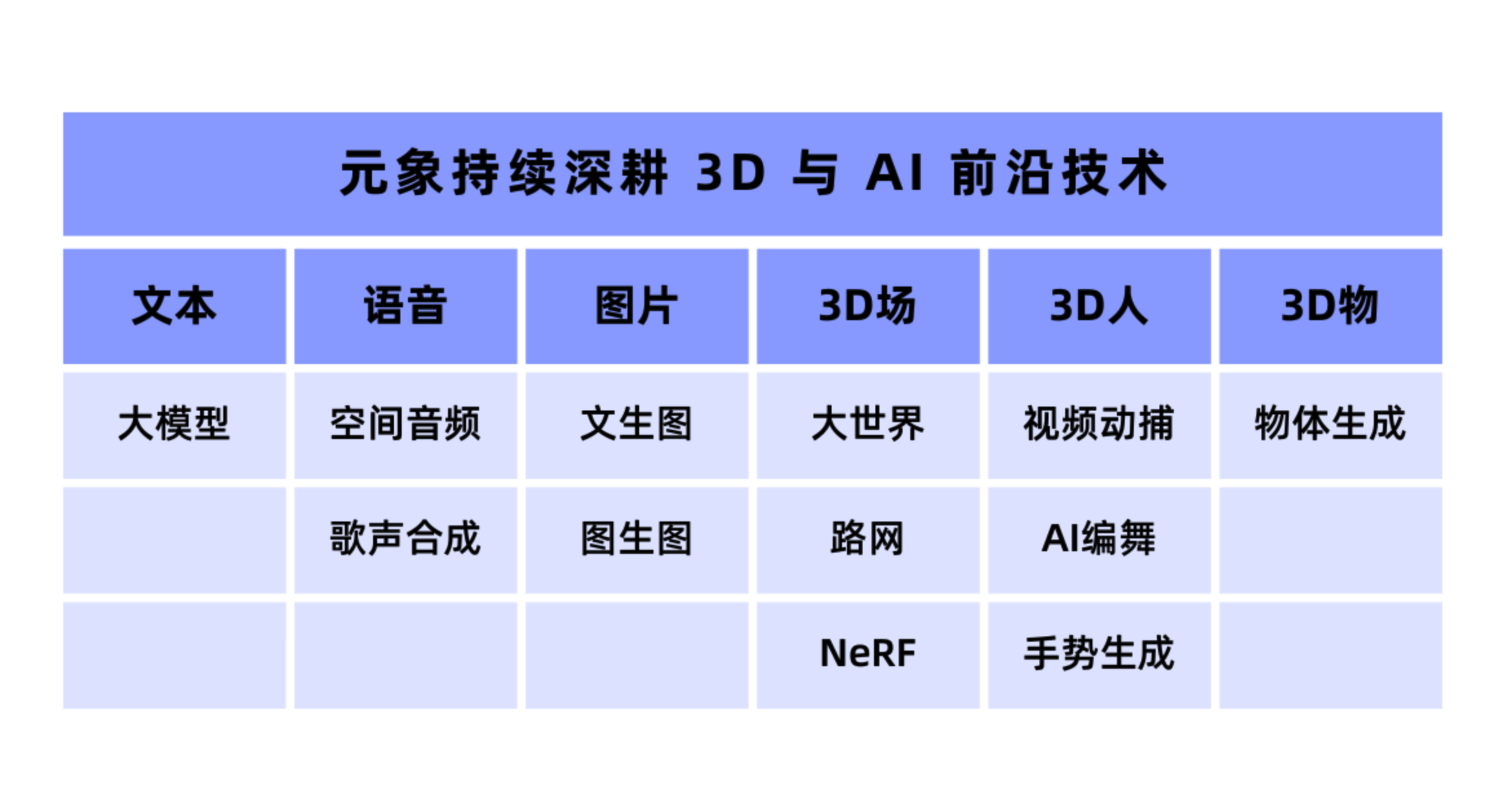
除此之外,大模型也可能會對高智能數(shù)字人、未來人機交互帶來顛覆性影響,這些是元宇宙內(nèi)容的重要組成部分,XVERSE-13B也將提供強大技術(shù)后盾。
基于強大的語言理解和生成能力,以及結(jié)合元象原有的3D圖形能力、語音技術(shù)能力,XVERSE-13B可以為高智能數(shù)字人提供更加豐富和多樣化的內(nèi)容來源和表現(xiàn)形式,使得高智能數(shù)字人更加逼真和智能。同時,由于大模型可以支持多種語言和任務(wù),并且可以根據(jù)用戶輸入或反饋進行自適應(yīng)調(diào)整,它們可以為未來人機交互提供更加靈活和個性化的交互方式,使得未來人機交互更加自然和流暢。
元象XVERSE創(chuàng)始人姚星表示:“真實世界的感知智能(3D),與真實世界的認知智能(AI),是探索通用人工智能(AGI)的必由之路,也是元象持續(xù)探索3D與AI前沿技術(shù)的動力。”作為“端云協(xié)同”3D互動技術(shù)的引領(lǐng)者,元象通過自研引擎和前沿AI算法驅(qū)動,為用戶打造全新元宇宙體驗,助?各?業(yè)3D化,實現(xiàn)自由「定義你的世界」愿景。

在《人工智能大模型產(chǎn)業(yè)創(chuàng)新價值研究報告》中指出:大模型產(chǎn)業(yè)價值的關(guān)鍵,在于降低人工智能的使用門檻,將其特征與能力與各種場景結(jié)合,以實現(xiàn)場景效率的提升。開源大模型可以通過大規(guī)模的數(shù)據(jù)和參數(shù),學(xué)習(xí)到更多的語言和知識,從而提高人工智能的通用性和泛化能力。同時,通過預(yù)訓(xùn)練和微調(diào)的機制,簡化人工智能的開發(fā)流程,降低人工智能的技術(shù)門檻和成本。
正如元象XVERSE所述,XVERSE-13B已基本實現(xiàn)國產(chǎn)可替代,公司也期待為國產(chǎn)大模型發(fā)展貢獻一份力量。開源大模型本意還是讓更多的開發(fā)者、用戶可以直接部署和使用,推動生態(tài)和產(chǎn)業(yè)的發(fā)展為主。同時企業(yè)也支持在許可范圍內(nèi),開發(fā)者對XVERSE-13B 修改得到模型衍生品,對于模型衍生品中付出創(chuàng)造性勞動的部分,開發(fā)者可以主張該部分的知識產(chǎn)權(quán)。
大模型之家認為開源大模型為社會的可持續(xù)發(fā)展提供了豐富的資源和可能性,作為人類共同智慧的橋梁,開源大模型將為社會創(chuàng)造更加智能、包容和進步的未來,引領(lǐng)我們邁向一個全球化、數(shù)字化的智慧文明時代。